Engineering
Segmenting Vertebrae in X-RAY Scans Using Mask R-CNN
Introduction
Artificial disk replacement surgery is a complex procedure which also carries many risks for the doctors performing the procedure due to radiation exposure, all the more so because same team of people are involved in many different surgeries of the same type. Multiple x-ray scans have to be taken during surgery to have clear visibility of the procedure and to reduce risks of surgery complications, especially since the procedure is performed in proximity to the patients spinal cord. To reduce the radiation exposure, low-dose scans must be taken during the surgery, but the trade off is lower image quality.
Currently there are many image enhancement techniques that are used to solve the problem of low medical image quality, but a large portion of them is applied on the whole image. Spinal vertebrae have individual freedom of movement as well as group movement, so it would be more feasible to apply image analysis techniques on individual vertebrae rather than the whole x-ray scan.
In this article, we will describe how framework for object instance segmentation can be leveraged to identify individual vertebrae. We hope this demonstrates a proof of concept that instance segmentation should be used in situations where different areas of image have to be analyzed and enhanced individually independent to the rest of the image.
Methods
Overall strategy was conceptually simple: Use framework for object instance segmentation to recognize areas, or zones of interest (ZOI) which contain one vertebra each, on low-dose x-ray scan (lower dosage of radiation results in lower image quality). Output from this process would be a collection of ZOI's recognized on the low-dose scan. We would then repeat the same process on the initial high-dose x-ray scan which is usually taken before the disk-replacement procedure begins. This would conclude the proof of concept, demonstrating feasibility of using neural network and object segmentation framework to assist disk replacement surgery procedure. The client already had the technology to locate and replace ZOI's on low-dose scan with corresponding ZOI's from the high-dose scan with the usage of 2D geometric transformations (only translation, rotation and scaling is allowed). End result would be a picture with much better visual quality which could be used by the surgeons performing the procedure.
Mask R-CNN
Mask Regional Convolutional Neural Network (Mask R-CNN) is a conceptually simple, flexible, and general framework for object instance segmentation. Without bells and whistles, Mask R-CNN outperforms all existing, single-model entries on every task, including the COCO 2016 challenge winners. It detects objects in an image while simultaneously generating a high-quality segmentation mask for each instance. The method, called Mask R-CNN, extends Faster R-CNN, a unified network for object detection, by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition. Mask R-CNN is simple to train and easy to generalize to other tasks, such as allowing you to estimate human poses in the same framework. Mask R-CNN is a two stage framework which consists of a deep fully convolutional neural network that is used for feature extraction over an entire image - backbone, and the network head for bounding-box recognition and mask prediction.
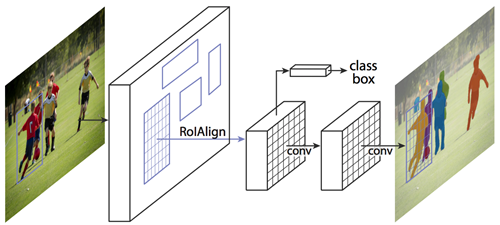
We opted to use open-sourced implementation of Mask-RCNN on Python 3, Keras, and TensorFlow. The model generates bounding boxes and segmentation masks for each instance of an object in the image.
Training dataset
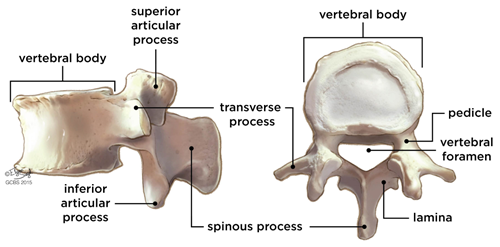
Pre-trained weights were used as a starting point to train our own variation of the network. We used the existing training and evaluation code located on the repository. First we needed to classify various segments of the spinal column and spinal vertebrae that were of interest to us:
- Body
- Spinous processes
- Pedicles
- Transverse processes
Existing pre-trained dataset did not contain the classes of spinal vertebrae that we defined, but since it was trained on over 120K images, trained weights have already learned a lot of the features common in natural images which helps. Client provided us with a set of scans which we transformed into Common Object In Context (COCO) dataset of scans which is necessary step for training weights. We used one portion of the dataset to retrain the weights (approximately 2000 images). Due to smaller sample size, it was even more convenient to use a pre-trained weight set to achieve good accuracy. Other portion of images was used to test out the results. After achieving a satisfactory level of accuracy (everything above 90% was acceptable) we added in the code to extract masks after the mask evaluation process was completed.
Results and Conclusion
Using OpenCV library for python we cross-referenced the mask locations on the unprocessed images and extracted the pixels underneath the masks, thus getting a collection of images containing individual ZOI's. The whole process was a success, and our results would serve as an input to the clients existing framework which already had capabilities to perform 2D geometric transformations and image enhancements. Results we obtained serve as a proof of concept that you can use Mask R-CNN to detect individual vertebrae(ZOI) on a scan, and then use different alignment transforms for different vertebrae,find each correct alignment and display the result to the doctor.
This article explains how frameworks for object instance segmentation on images can be leveraged in medical image analysis. We presented and discussed the application of Mask R-CNN framework in x-ray scan analysis. Process of deep neural network training for specific object recognition is explained, and advantages of using pre-trained weights to compensate for lower sample size is discussed. Depending on operative procedure complexity and risks surrounding the procedure, different accuracy constraints can be imposed on the object segmentation framework, and our agreed upon acceptance criteria for this proof of concept project was 90%.
Get the full research paper here

Follow Us
Subscribe to Infinity Mesh
World-class articles, delivered weekly.