
Engineering
How to Build an Enterprise Game Platform for Millions of Players (2/3)
In the previous article, I explained how we began developing a simple Rock, Paper, Scissors game platform that quickly gained popularity across the United Kingdom. As previously stated, we built a game backend system using microservices architecture, which allowed us to divide domains into autonomous units, giving us an excellent opportunity to control scalability.
We discovered several services, each with its domain and set of responsibilities, by following the same set of rules. In this article, I'll attempt to explain where we encountered a performance issue with this architecture. Additionally, I will try to provide details on how to approach the problem for a prompt resolution and how the chosen model became a game-changer and altered our perception of the system.
A high-level overview of the system design
When people consider gaming, the first thing that frequently comes to mind is gameplay. This is reasonable, as playing a game entails numerous challenges, such as competing against an opponent creates some tense moments, especially when you win.
While the gameplay is unquestionably essential, numerous other factors contribute to the game overall balance. Several of these include game management, user and player management, and notification systems for tournaments. Additionally, auditing and fraud detection ensure that the system operates smoothly to provide complete insight into the game and ensure fair play. Leaderboard management also contributes to player engagement by increasing players' opportunities to compete against one another and tracking their stats regardless of when they last played.
We've divided each service into individual responsibilities to support the game with all of those elements, significantly reducing complexity caused by various factors.
As illustrated in Figure 1, the solution includes an abstract of the software system overall structure and the relationships, constraints, and boundaries between its components. To understand why this approach cannot scale beyond 10.000 concurrent players, it is necessary to comprehend the game and game play services, their design, and their interaction. Due to the complexity of the system, I will limit my writing to the scope of these two services.
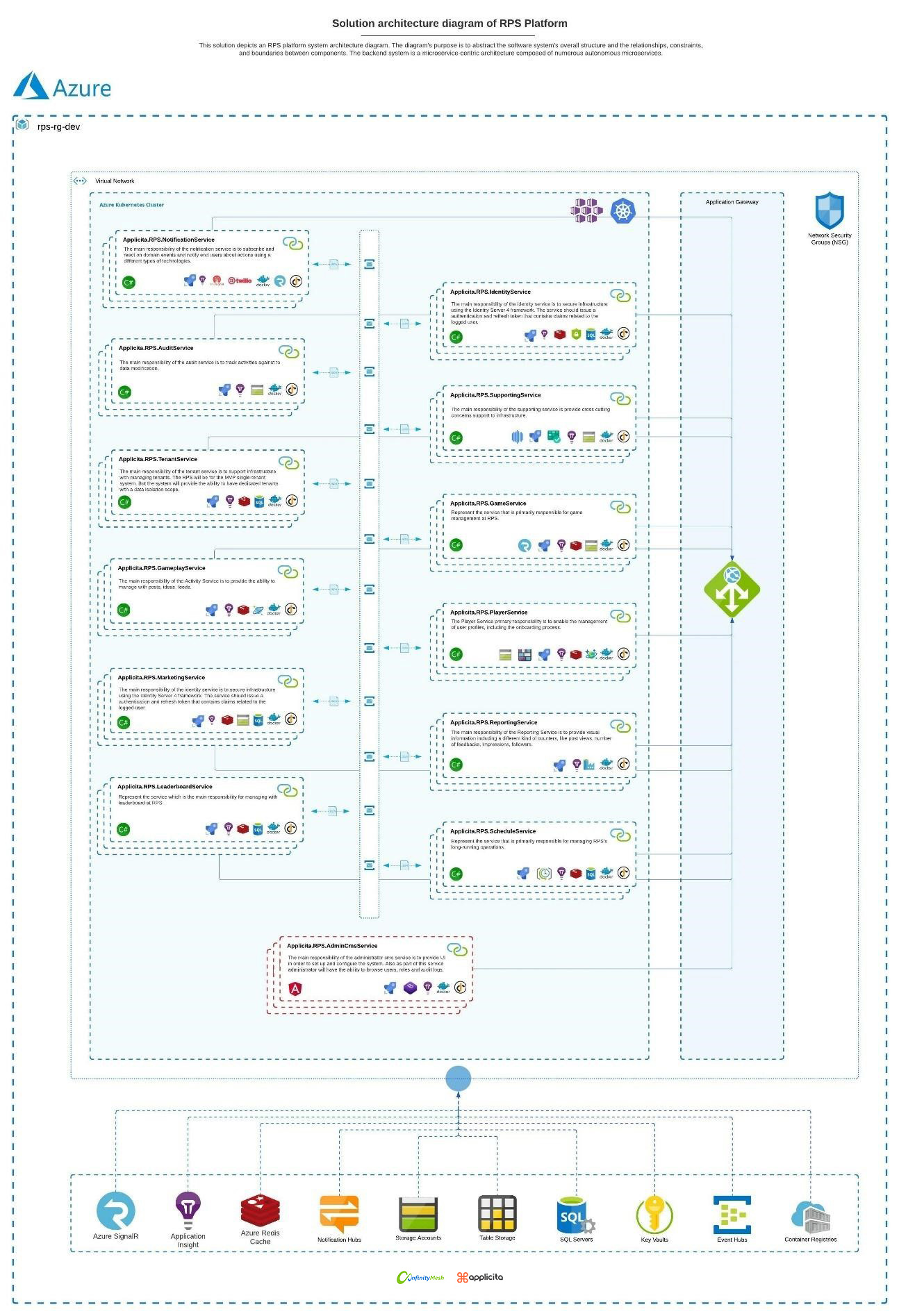
Figure 1 - Solution architecture diagram of RPS Platform
The design of the gameplay
The game has been designed to occur daily at pre-setup time. Obviously, this is configurable during the setup of a new game. The game manager can specify the date and time, recurrence, the winning and consolation prizes, and the game cap.
Once the configuration for the new game is complete, the system will listen for the next game. Five minutes before the game starts, the system will scan the candidate games and send notifications to players ensuring they do not miss the next game, like in figure 2.
Figure 2 - The notification center
Once they've joined the game, they'll spend approximately three minutes in the lobby before the tournament begins. Immediately after the player clicks on the notification and navigates to the client app, the Game Service will orchestrate the procedure for creating a player context for a particular game. When the application starts, the Azure SignalR Connection with the client is established. All subsequent communications with the client will be carried out over a Web Socket to maximize efficiency and minimize latency along the client-backend path.
After joining the game, the player will be placed in a lobby with all other players and wait three minutes before the game begins. When the three-minute wait in the lobby is complete, the game service will raise the event Game Started using Azure Service Bus. The message will be directed to the particular topic, and all other services will be able to react to this event and proceed as described in the specified domain.
Since gameplay service is also subscribed to the game started event, gameplay services can now prepare all necessary gameplay segments. Based on the fact that the event contains game-specific information, such as the Game Id and Tenant Id, we can acquire all pertinent information regarding that game. The gameplay service will gather all seated players in the lobby and transfer them to the game pool. Following this operation, the gameplay service will begin creating matches.
When the gameplay service creates new matches, the game service will receive the event that the game is ready. Because the game service has established a SignalR connection with the client, the service will send a signal with the match context to the client app.
When both players make moves and clients send the signal to the server, the match becomes a candidate for resolution. Additionally, the match is a candidate for resolution if any player does not make a move within ten seconds, which is the server-imposed match timeout. Once the client app receives the match context, it displays the match data and renders the appropriate screen based on the signal received. The client immediately begins a countdown clock, and players have 7 seconds to choose their next move. When the timeout period expires, both moves are transmitted to the backend via the same connection. When the game service receives the move signals, they immediately raise an event indicating the move has been accepted. Gameplay services have the option of reacting to the event according to implemented logic.
After determining the winner of the match, the gameplay service will invoke the resolved match event. The game service can now process an event message and return the result to the client. This indicates that the match has been successfully resolved, and clients can now display the match result. To provide the most efficient method of updating state, we designed the object to be identical to the one used for match found, which means that the client only needs to update the single object state based on data from the match context.
Since the game supports a golden life, the match context is aware of this data and keeps track of whether the player currently has a golden life or has redeemed it. Typically, when the player sees the match result and has completed redeeming golden lives, the client app has the opportunity of notifying the server that the player is ready for the next match, as illustrated in figure 3.
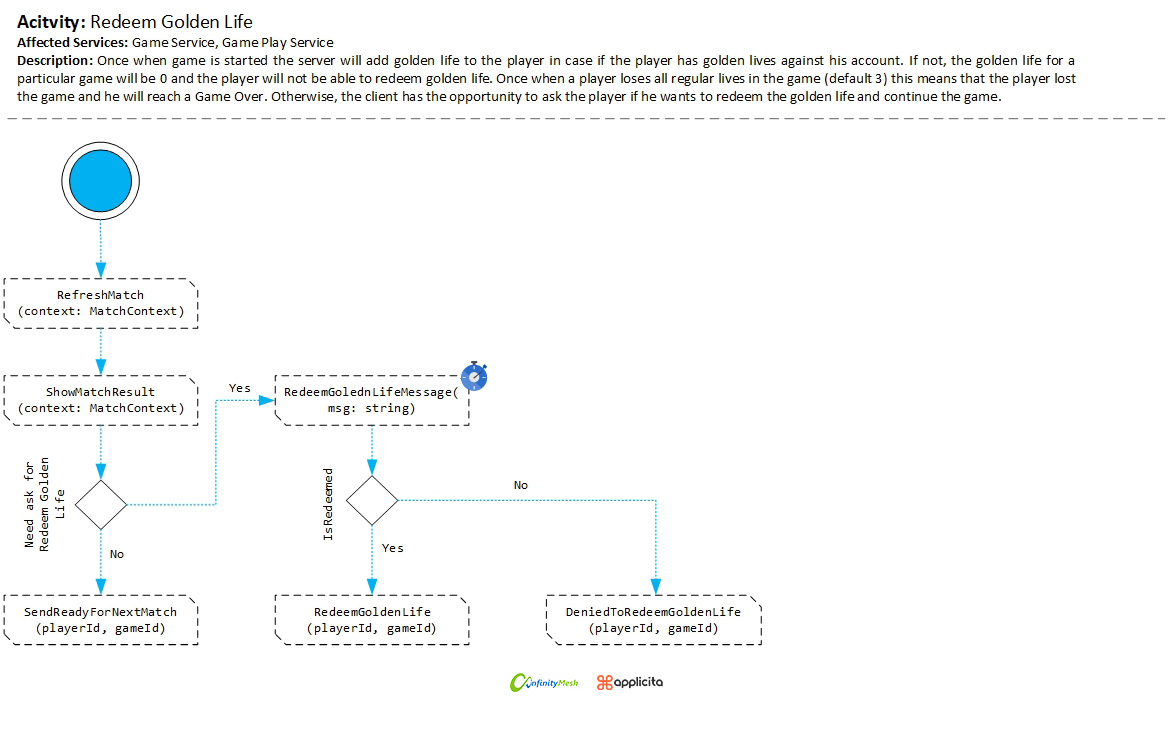
Figure 3 - Redeem golden life
The game service determines whether the player is eligible to participate in the next match - in which case, the player is labeled as a "waiting opponent" and placed in the game pool. If the service determines that the player is no longer eligible for the next game due to losing all lives, the client app will receive a game over the signal.
Because the game service is highly susceptible to client-server connection loss, the system will ensure that the player has the best possible experience in the event of a connection loss. If a player loses connection during a match and re-establishes it before the timeout expires, they may continue with the game. In essence, regardless of whether a player is connected, the server will determine if the player is eligible to play in the next match. If a player meets the eligibility requirements, they will be added to the game pool and remain there until lives are lost.
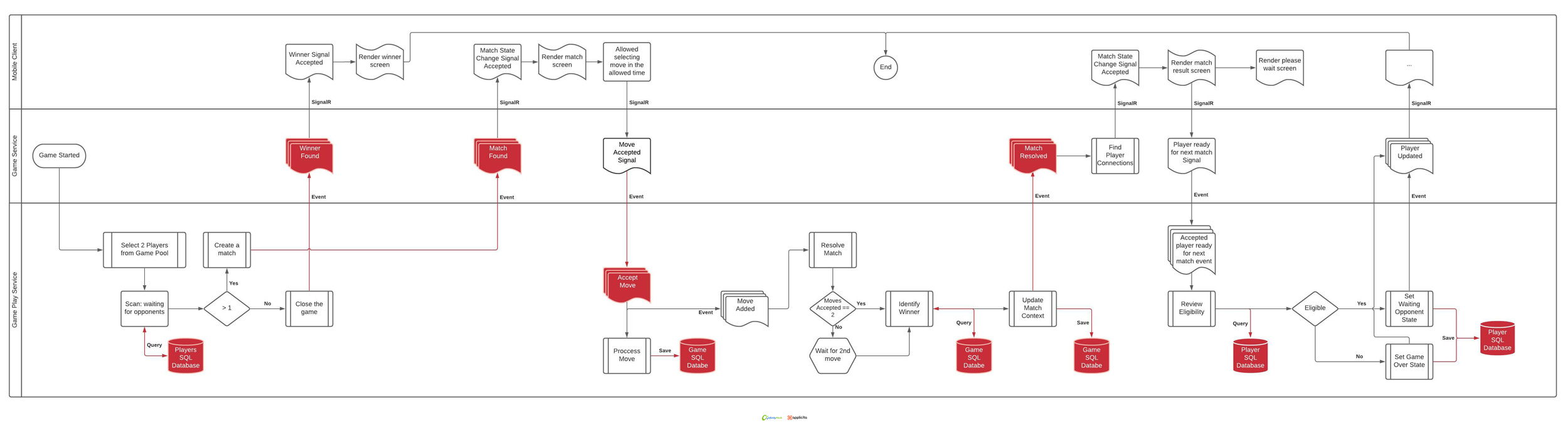
Figure 4 - Representation of roughly game flow
Uncovered bottlenecks
The previous section discussed the gameplay flow, which is summarized in Figure 4. In the same figure, you should see some segments labeled in red alongside the lines. The red segments represent bottlenecks that we discovered through our telemetry data.
We can divide the bottleneck issues into two categories that have begun to impair the system performance: latency between components and pressure on the storage. If you carefully read the previous section, you will notice that we make a query to the database in order to complete a particular action for each interaction. Similarly, we isolated the gameplay service from the end client, and they will communicate only through the middle service that runs the game. This is, in some ways, a natural pairing for domain identification and boundary configuration, but it could pose a problem in another hand.
Now, let's try to break down the process of resolving the match. To keep things simple, we'll use the most straightforward case without losing the connection for both players. Once the time limit for sending the move has expired, the client application will return the move data using signals which is by definition simple, as illustrated in Figure 5. Since the client application and game service are already connected, the game service will accept the move right after the payload is forwarded to the gameplay service to resolve the match.

Figure 5 - The payload for accepting a move in JSON format
The gameplay service will be subscribed to events such as Move Accepted Event. This means the service must wait for the message to be delivered by Azure Service Bus. If the message arrives, the service will attempt to resolve the match. If the client has not yet received the second move, the client is given a three-second time window in which to submit information about the other player's move. Within the three-second mechanism for determining whether both moves have been received, there is a check to resolve the match even before the allowed three seconds. As part of this process, the gameplay service, whenever they want to check if the target match is eligible for resolving, they have to query the database to retrieve enough information.
Let us now speak numerically and assume that we currently have 10.000 players in the game. Due to the tournament nature of the game, the critical component maintains a synchronization clock, which means they must send moves simultaneously with a delta of less than 10ms. Each player move must be entered into the database, which equates to 10.000 writes. Following that, when moves are received, the process of resolving the match is started. In the best-case scenario, we will need to make only one call to determine the eligibility for resolving the match; in the worst-case scenario, we will need to make five calls due to the exponential back-off setup. The latency has increased exponentially since we've increased the pressure on events to be pushed into queues/topics. As a consequence, the exponential back-off worsens increasingly,
As a result of constant latency per event, we will have more pressure on the database server, due to the increasing number of queries on the database. The system performance degraded as the number of players increased, and thus the number of events generated in a very short time interval. As you can see in figure 6. In the next section we will discuss how we resolved this issue and what shifted the paradigm in our model thinking.
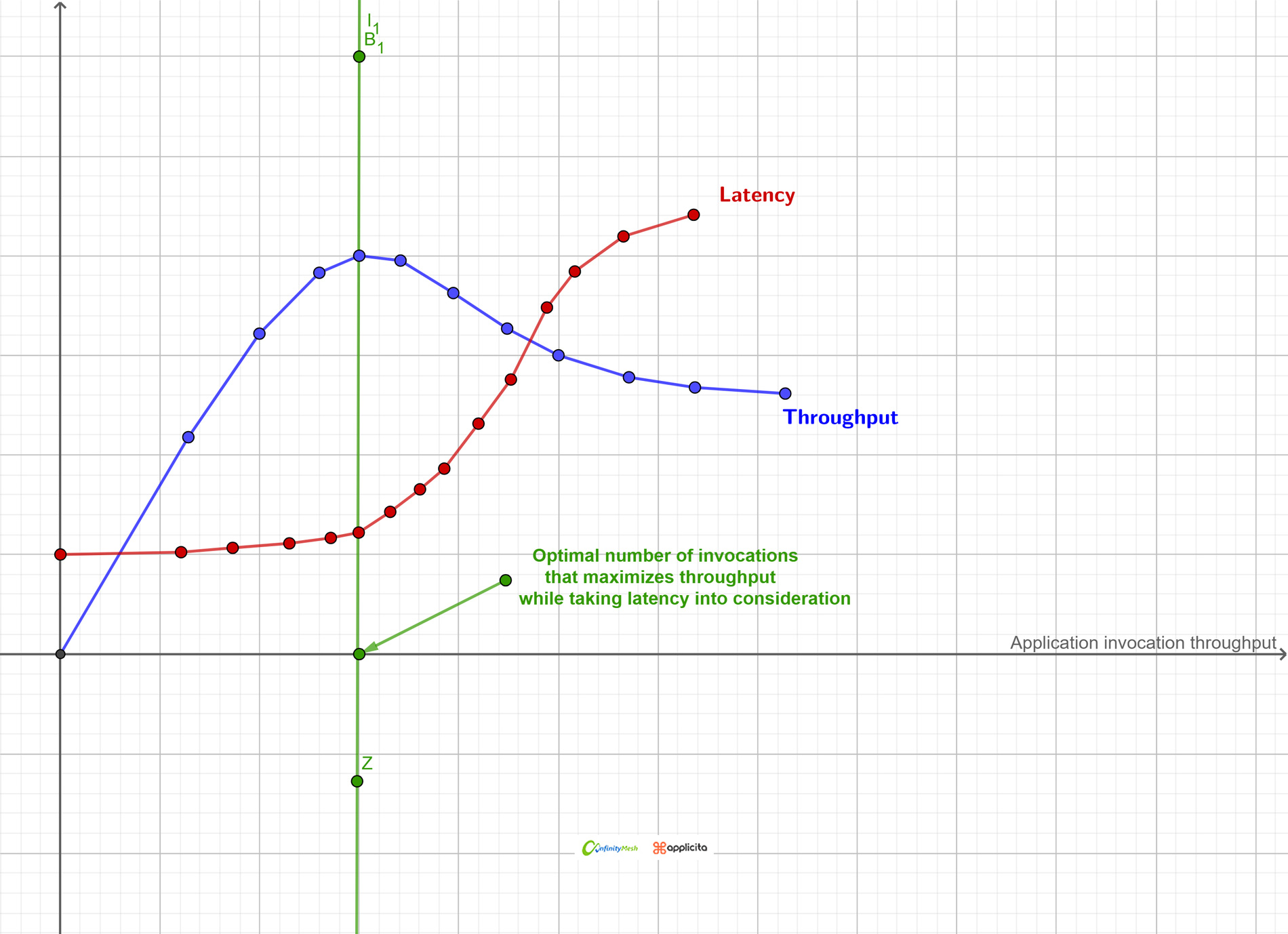
Figure 6 – Application invocation throughput
The game changer in our thinking model
When we realized we couldn't create a scalable model, we paused feature development and re-analyzed the overall solution in order to create a more scalable model. We were in a better position at this point than when we started architecting the game. We now have a better grasp on how data behaves across domains, on its nature and on its anatomy. All of these factors led to development of a suitable solution.
We decomposed each process to determine how we could reduce the number of steps and reliance on external components such as SignalR, the database, and distributed cache, while also attempting to reduce the number of unnecessary events. We estimated the game duration based on historical data that aided in our understanding of the data. As a result, we conclude that it is safe to consider gameplay data to be transient by nature, as data types such as matches, moves, connections, and states all have a short lifespan. Moving forward, we identified an opportunity to completely eliminate database usage while also halving the number of events generated during gameplay.
As a result of the data nature, we came to believe that this model fits the actor paradigm model perfectly. Thus, the game is an actor, and matches are child actors, and players are child actors, and so forth. We begin by encapsulating the existing objects in state and behavior and then transferring all communication exclusively via messages delivered to the recipient mailbox, resulting in zero events and all data persisting in memory. This became the mental framework around which Roshambo Live V2.0 was developed.
We recognized that a significant technical constraint exists that cannot be easily resolved due to the nature of microservice architecture. Due to the fact that all services exist as autonomous units and communicate asynchronously, they require a distributed point such as a service bus to enable an event-driven approach. As a result of our modeling, we realize that we are seeking a single large machine rather than autonomous nodes.
Due to the fact that this cannot be accomplished without a traditional horizontal scalability model, we began investigating technologies that could assist us in accomplishing it, as we need to ensure a proper scalability model based on best practices.
Conclusion of the Second Round
In this article, we discussed the performance issues we encountered with the current architecture and conventional model thinking in terms of object-oriented paradigms.
We describe the approach we took in order to gain a better understanding of the system behavior and data, as well as how we came to believe that the actor model paradigm could help us.
The following article will discuss actors in greater detail and will also examine the technology that enables us to run 100.000 players for the first test successfully. Please stay in touch if you wish to learn more about it.

Subscribe to Infinity Mesh
World-class articles, delivered weekly.