
Engineering
CMS the Engineers' Way
Are you interested in knowing what is a CMS and where did it come from? What started the CMS revolution and the motivation behind it? What about discussing building the CMS itself and its components? In this series of articles on CMS the engineers’ way, we are embarking on a journey that explores CMS since its inception and we are going to discuss its various components, different architectures and development.
What is a CMS?
Let’s assume that you have content you would like to update on a daily basis. And let’s say that you are not the only content creator on that page, moreover, you have a main editor on board who is reviewing, approving or rejecting the content you just created. Now, if you have been in the early ages of the internet you would’ve had to take care of everything manually, from creating the HTML page, style and its layout, including JavaScript, to placing the images in correct position and making sure that your post matches the website overall theme (or template in this case). What about keeping track of authors and co-authors on published content on your website? How about scheduling publication date/time and managing marketing campaigns?
Since this might be cumbersome for regular creators with little technical background and care about delivering the content, Content Management Systems (CMS) comes to the rescue. At its core, CMS is a streamlined content creation and management platform, as shown in this very simplified diagram below:

Figure 1 10,000 meters view of CMS
This doesn’t only help with content creation, but management as well. Since CMS can put an order to all items/articles that authors and coauthors have created and even keep track of the document versions. Furthermore, it hides all the technical details of creating content from creators and/or curators so they can focus solely on the content creation process. However, there is more into CMSs in general than just content creation and editing which this series explores in depth. But before we embark on this journey, we need to make a quick stop at the history station so we can understand the motivation behind CMSs and its development in general.
Origins
By the time of writing this article, according to W3Techs, more than 150 CMSs that has been created so far. Each are covering certain areas and addressing certain problems that other CMSs probably didn’t emphasize it enough. What makes it probably more interesting is that the majority of websites today are powered by some sort of CMS (e.g. BBC, Medium, TechCrunch, etc.), at least from the statistical standpoint as shown below.
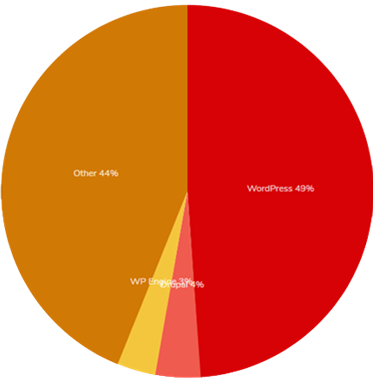
Figure 2 CMS usage distribution (From Trends BuiltWith)
Couple resources already have shown that WordPress is currently leading the statistics with powering almost 50% of websites on the internet that are using a CMS. You can also double check the statistics from W3Techs, which isn’t far from the above BuiltWith statistics. Hence chances are quite big that you are following and/or regularly visiting a website that serves its pages through a CMS.
So, how did it all begin?
When I’ve started researching for the origins of CMSs, I was surprised that the first result to turn up was a patent, filed by Makoto Saito with priority to JP06-267200 in October 1994. The patent named “Digital content management system and apparatus” (you might find it under Data copyright management system and other similar names depending on the country it was applied in), which was assigned to Mitsubishi Corporation later in June 1997. Interestingly enough, looking at the basic diagram (figure 3), one might see some similarities with modern overview of CMSs interaction today.
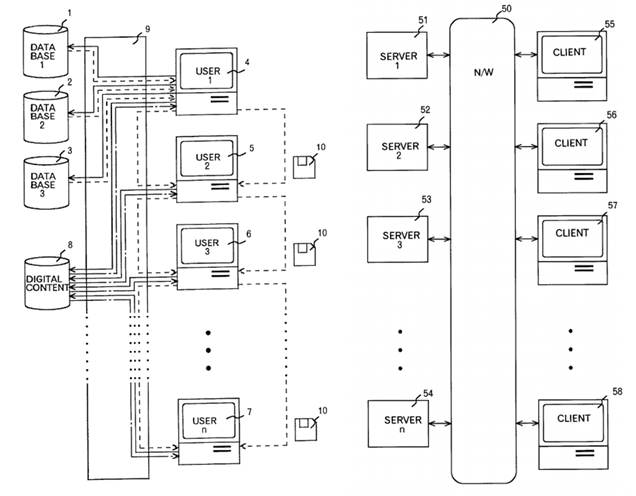
Figure 3 Structural view of the CMS and its server architecture (from Makoto Saito pattent)
It doesn’t only stop there, the patent discusses the apparatus (i.e. the computer) architecture with the typical CPU, local system bus ROM, EEPROM and PCI bus system. Furthermore, it discusses how all these components fit and/or connected together in relatively detailed manner. Reading further into the patent, one can find more details such as: handling digital copyrights and keeping track of changes in documents uploaded to the server, encryption and decryption of data as well as authentication and authorization. Moreover, the author (or the inventor rather) discusses the distributed nature of the CMS and how data can be available over multiple servers, however it is strictly within the local network, therefore this system is meant for the operation of the organization only.
Another patent…
A second patent filed at the United States Patent in 2004 carrying number US 6,804,674 B2, titled a “Scalable content management system and method of using the same”, which describes in 16 pages what this system is all about. This patent might to some, resemble the modern-day CMS which we are familiar with. It discusses content repository, and its scalability with size and users along with authentication manager.
Moreover, that patent is not only limited to keeping track of articles within the organization, but with customers and partners of the organization. One can see that the use of metadata, images and video clips has been addressed in detail, which shows the multimedia aspect of the proposed CMS can handle. Also, according to the patent, the system architecture is scalable and can span multiple nodes in case of exceeding number of users per node.
Of course, one could argue that this patent came much later since Drupal started on May 2000 according to their GitHub repository history, followed by the release of WordPress in 2003 and later Joomla in 2005.
Going back even more
Internet as a concept existed since the 1960s being popularized by J.C.R. Licklider, one could think there was at least an evidence of some earlier and more primitive form of a CMS. Hence, I’ve traced steps back to March 1989, May 1990 with the Tim Bernes-Lee information management which has been proposed in CERN.
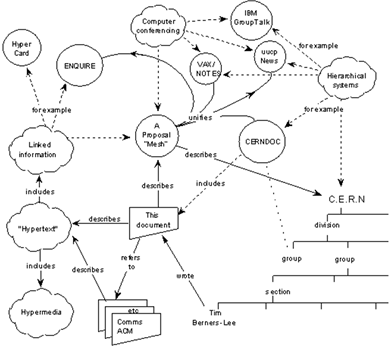
Figure 3 Structural view of the CMS and its server architecture (from W3)
Looking at the description of the proposal, authors had difficulties with tracking people, work and their communication. Moreover, people who are joining CERN have 2 years length of stay, therefore information get lost often, hence, they wanted to keep a static record of work and contribution that has been made by researchers within the institution. Furthermore, the proposed system should keep track of people, groups of people, projects, concepts, documents with their versions and goes as far as discussing the problem of content trees. And here is small bit that might bring a smile to you, under the “Bells and Whistles” title, “the addition of graphics would be an optional extra”.
True it was the basis of WWW, however at its core one could interpret it as some sort of a CMS, since the proposal is about index, searching by keywords or author, formatting and publishing, which the CERN proposal relatively checks all these boxes.
Interestingly, modern day CMS is not far from these proposed systems, but it has been carved, shaped and perfected over the years of technological evolution and the million man-hours put into creating it. You can find the links to all resources discussed in this article and more in the references section.
Next articles takes’ a deeper look at CMSs in general, their roles, what problems they solve and how they fit in in the web 3.0 in general.
Final note:
For the research gurus out there, while I was looking at old research papers and patents regarding content management systems in general, I’ve spotted this paper in the references multiple times: Getting it out of Our System Theordore H. Nelson information Retrieval: A critical review Washington DC Thompson books 1967 p 191-210.
Unfortunately, by the time of writing this I haven’t got my hands on it as I wanted to see the connection with the CERN proposed system beyond just the “Hypertext” proposal, since it was referenced first, hence thought it is interesting to mention for those who are curious about it and probably have access to it might give it a read.
References
- https://www.bbc.co.uk/blogs/internet/entries/a4ff8c67-7b3c-322c-b771-d43323b221cb
- https://www.bbc.co.uk/blogs/internet/entries/47a96d23-ae04-444e-808f-678e6809765d
- https://patents.google.com/patent/US6424715B1/en
- https://cds.cern.ch/record/369245/files/dd-89-001.pdf
- https://github.com/drupal/drupal/releases?after=4.0.0
- Martinez-Caro, J.-M.; Aledo-Hernandez, A.-J.; Guillen-Perez, A.; Sanchez-Iborra, R.; Cano, M.-D. A Comparative Study of Web Content Management Systems. Information2018, 9, 27. (https://www.mdpi.com/2078-2489/9/2/27/htm)
Trending Articles
Follow Us
Subscribe to Infinity Mesh
World-class articles, delivered weekly.